






A new research paper from the Center for Long-Term Cybersecurity examines how safeguards designed for search engines could be adopted by developers of AI systems like ChatGPT. The report, Survey of Search Engine Safeguards and their Applicability for AI, was co-authored by Evan R. Murphy, Nada Madkour, Deepika Raman, Krystal Jackson, and Jessica Newman, researchers affiliated with CLTC’s AI Security Initiative.
“Over the past three decades, search engines have encountered a wide range of potential harms and misuse risks, including the spread of misinformation, dissemination of extremist content, privacy violations, and threats to national security,” the authors write. “In response, a variety of safeguards to mitigate these risks have been developed for search engines and tested over time…. This paper reviews existing search engine safeguards and analyzes their potential relevance to AI systems such as conversational agents.”
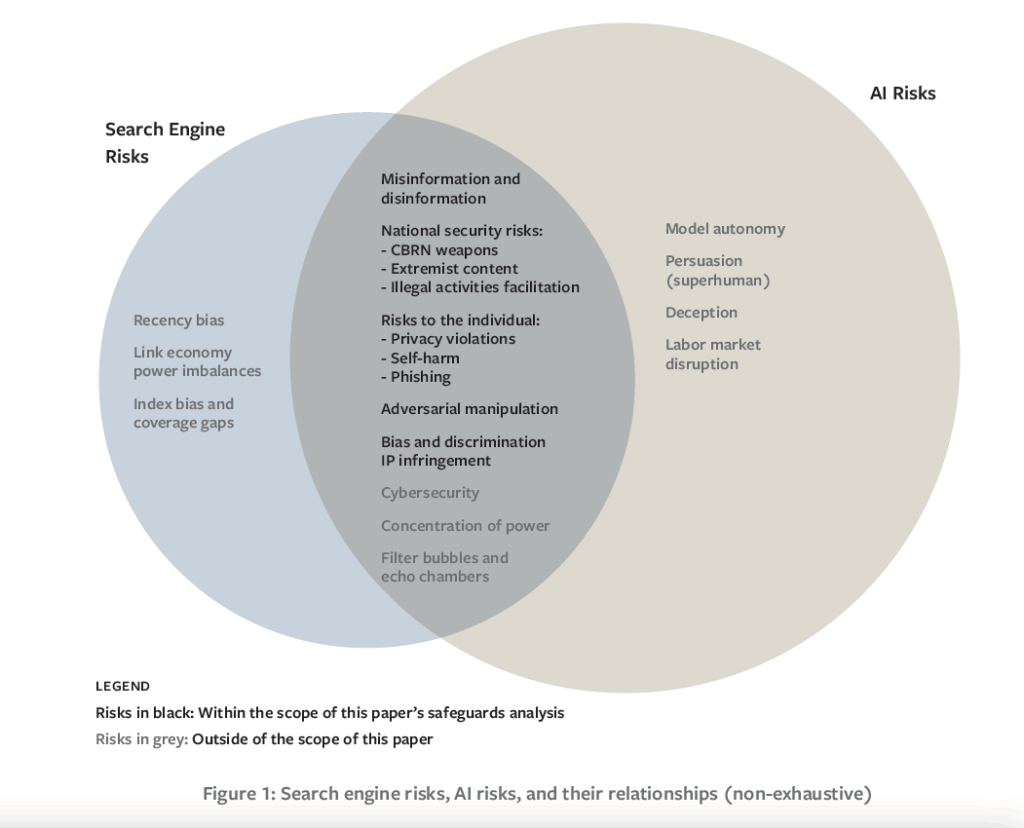
The report focuses on six categories of risk that are present for both search engines and AI, including the potential to spread misinformation and disinformation; national security risks (i.e., enabling access to dangerous or sensitive information); risks to the individual, such as potential infringement of privacy, surveillance, or disclosure of personal data; adversarial manipulation, e.g., external manipulation of search results; bias and discrimination, when search or AI algorithms have built-in harmful biases; and intellectual property infringement.
The paper then analyzes eight risk-reduction techniques that have been developed to address these risks in the context of search engines, including the delisting or purging of dangerous content, the employment of large numbers of “human raters” (i.e., people who are employed to evaluate system outputs for potential harms), the integration of fact-checking services, protections against malvertising (i.e., advertisements used for malicious purposes), and collaborations with national security agencies, among others.
Through their research, the authors identified certain safeguards that appear both “highly relevant to and underutilized in today’s AI systems.” Their results suggest that AI developers could improve their mitigations of the six risk categories by expanding their use of human raters, and by integrating fact-checking measures into model responses.
“Two other safeguards — removing harmful content and malvertising mitigations — also appear promising, but seem more relevant or ripe for application to future AI systems,” the authors write, due to reasons discussed in the paper. “While our cross-domain analysis has limitations, our findings suggest that valuable lessons from search engine safeguards could help inform the development of safer and more secure AI systems.”
This research was conceived during the authors’ participation in the U.S. Artificial Intelligence Safety Institute Consortium (AISIC), and an earlier version of the paper was presented to AISIC Task Force 5.1 in December 2024.



